发布日期:2024-08-08 04:31 点击次数:113

最近的英伟达似乎步入了风雨飞舞婷婷激情成人。
继其最强AI芯片被曝量产宽限、市值挥发超3000亿好意思元之后,英伟达又被404Media曝出,在未经授权的情况下,从YouTube、Netflix等平台合手取视频内容,用于检讨其尚未对外公布的AI视频模子。
里面邮件和Slack聊天记载显现,尽管英伟达职工对使用这些数据集的正当性和伦理问题建议了质疑,但公司不停层暗意这些步履已得到高层批准,并辩称其步履适合版权法。
值得一提的是,在2月末的里面接洽中,英伟达说起了其正在使用的多个数据集,其中就包括HD-VG-130M。
后者是一个包含1.3亿个YouTube视频的数据集,由北京大学的接洽东说念主员构建而成,而其使用许可讲授确法例仅限于学术接洽。
英伟达的作念法更像是当下大多数AI公司的一个缩影。
当用户仍是被视作“数据支款机”,除非里面东说念主士曝光,不然外界确实是难以清爽你我的作品是否仍是沦为AI检讨的养料。
简言之,东说念主类依旧是食品链尖端的虚耗者,但咱们也不能幸免成为了AI发展供应链中的一员。
以下为外媒404Media的爆料原文,由GPT-4o翻译,enjoyit~
用YouTube视频喂养模子,每寰宇载十分于80年的视频量
404Media得到的里面Slack聊天记载、电子邮件和文献显现,英伟达从YouTube和其他多个起首合手取视频,以为其AI产品编译检讨数据。当被问及使用受版权保护内容检讨AI模子的法律和伦理问题时,英伟达辩称其作念法“完全适合版权法的字面和精神。”
404Media检察过的英伟达里面对话显现,当职工对使用由学者为接洽想法编制的数据集和YouTube视频可能带来的法律问题建议疑问时,司理告诉他们,公司高层已批准使用这些内容。
一位前英伟达职工(404Media授予匿名权以接洽英伟达里面经由)暗意,职工被要求从Netflix、YouTube和其他起首合手取视频,以检讨英伟达的Omniverse3D宇宙生成器、自动驾驶汽车系统和“数字东说念主”产品的AI模子。
该名目里面称号为Cosmos(但与公司现存的Cosmos深度学习产品不同),尚未公拓荒布。
来自名目指引的电子邮件显现,Cosmos的谋略是构建一个起初进的视频基础模子,“将光传输、物理和智能的模拟采集于一处,以拓荒对英伟达要害的各式卑鄙应用。”
一张通过404Media得到的电子邮件展示的图表显现,Cosmos模子若何应用于不同的英伟达产品。
公司为该名目树立的频说念内的Slack音信显现,职工使用一种名为yt-dlp的开源YouTube视频下载器,结合造谣机刷新IP地址,以幸免被YouTube禁止。
据音信显现,他们尝试从包括Netflix在内的多个起首下载完满的视频,但主要聚合在YouTube视频。
404Media检察过的电子邮件显现,名目司理接洽使用20到30台AmazonWebServices的造谣机每寰宇载十分于80年的视频量。
英伟达接洽副总裁兼Cosmos名目精致东说念主刘洺堉在5月的一封电子邮件中暗意:“咱们正在完成v1数据管说念的终末定稿,并确保敷裕的计较资源,以构建一个视频数据工场,每天生成十分于东说念主类一世视觉体验的数据量。”
英伟达里面的对话和教唆显现,职工接洽了公司在想象芯片和API时的法律和伦理考量,这些芯片和API推动了生成式AI的兴起,使其成为宇宙上最有价值的上市公司之一。
这也凸显了行业内最大的公司,如Runway和OpenAI,对行为检讨AI模子数据的内容有着难以知足的需求。
英伟达的一位发言东说念主在给404Media的一封电子邮件中暗意:
咱们尊重系数内容创作家的职权,并笃信咱们的模子和接洽使命完全适合版权法的字面要乞降精神。版权法保护特定的抒发姿色,但不保护事实、不雅点、数据或信息。任何东说念主王人可以从其他起首学习事实、不雅点、数据或信息,并用它们来创造我方的抒发。合理使用也保护将作品用于变革性想法的职权,举例模子检讨。
当被问及英伟达使用YouTube视频行为模子的检讨数据时,Google的一位发言东说念主告诉404Media,该公司的“此前的褒贬仍然适用”。
其中YouTube首席实践官NealMohan暗意,淌若OpenAI使用YouTube视频来优化其AI视频生成器Sora,这将明确违抗YouTube的使用条件。
Netflix的一位发言东说念主告诉404Media,Netflix与英伟达没关联于内容获取的公约,况且该平台的服务条件不允许合手取数据。
参与该名想法职工建议的关联法律问题的疑问每每被名目司理驳回,他们暗意在未经许可的情况下合手取视频的决定是“高层决定”,职工无需驰念,对于什么组成对受版权保护内容和学术、非生意用途数据集的公说念、伦理使用的话题被视为一个“未处置的法律问题”,他们会在异日处置。
咱们的窥伺凸显了这些科技公司在将大王人受版权保护的内容合手取到数据聚合,用于检讨宇宙上最有价值的AI模子时的“不问自取”气派。
英伟达高管提议,北大学术数据集也遭滥用
2024年2月,英伟达的首席科学家FrancescoFerroni在名为#cosmos-dataset-creation的英伟达公司Slack频说念中写说念:
“各人好,@SanjaFidler向我提到了一个团聚大王人精选视频数据集以进行生成建模的倡议。咱们合计,早先汇总系数里面可用的(公开或里面下载)的视频数据集,以幸免访佛服务,是很有道理的。”
(注视:SanjaFidler是英伟达的AI接洽副总裁。)
随后,Ferroni流畅了一个包含数据集流畅的电子表格,其中包括MovieNet(一个包含6万个电影预报片的数据库)、WebVid(一个由Github上的素材图片编译的视频数据集,其后因Shutterstock的住手奉告而被其创建者删除)、InternVid-10M(一个在Github上的包含1000万个YouTube视频ID的数据集),以及几个里面拿获的视频游戏画面数据集。404Media仍是从Slack对话的截图中删除了初级职工的姓名。
咱们包括了几位参与该名想法高等工程师和高管的名字,因为他们在AI行业中以指引者身份享有公开著明度。
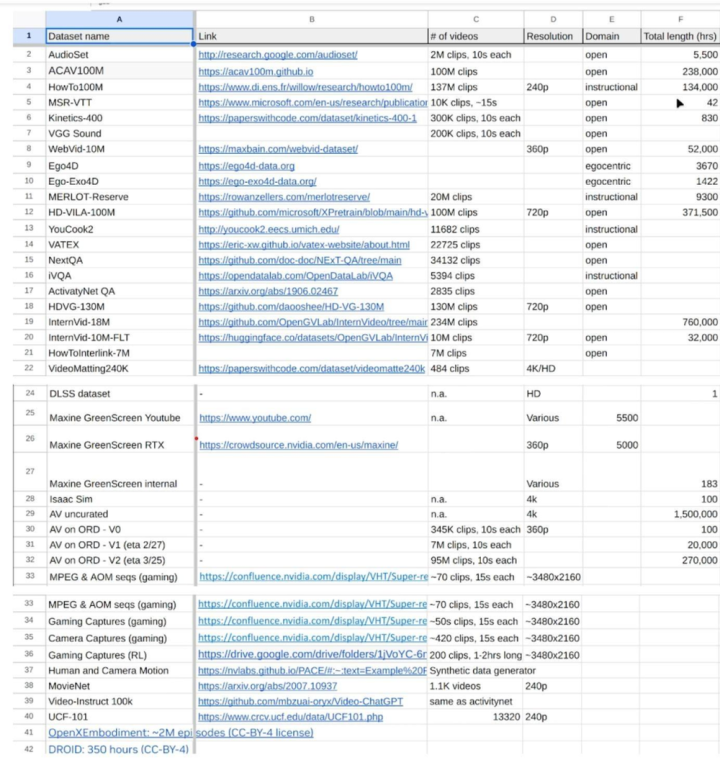
Ferroni流畅的电子表格展示了名目使用的数据集
在二月份的后续接洽中,工程师们谈到他们获取的数据集时,其中包括HD-VG-130M,这是一套包含1.3亿个YouTube视频的数据集。该数据集由中国北京大学的接洽东说念主员创建,其使用许可声明指出只可用于学术用途。
该数据集的Github页面上写说念:“通过下载或使用数据,您默契、承认并应许以下公约中的系数条件。”
该页面强调“只可用于学术用途。HD-VG-130M数据聚合的任何内容仅供学术接洽使用。您应许不复制、交游或用于任何生意想法。不容分发。尊重原始起首个东说念主信息的狡饰。未经版权领有者的许可,不得对数据集内容进行任何口头的播送、修改或任何其他类似步履。”
在系数名目过程中,由接洽东说念主员和学者编制并公开的数据集被视为可以解放使用于英伟达的模子。AI接洽东说念主员越来越柔顺他们公开的数据集的适合使用,包括伦理和法律方面的使用。
麻省理工学院数据溯源倡议的RobertMahari告诉404Media,在往时的一年中,他们看到接洽数据集的非生意使用许可的使用率显耀加多,这标明学者们试图戒指他们使命的生意使用。为接洽用途编制的数据集与生意用途的数据集在想法上有显耀不同。
“当学者发布各人数据集,尤其是针对特定任务的数据集时,咱们可能不会极端检讨这些数据是否存在某些类型的偏见或西方中心主义之类的问题。淌若这些不是接洽的重心,那么就不会进行检讨,”Mahari说。“因此,淌若一位学者在许可中注明‘仅供学术使用’或‘请不要以非预期姿色使用这些数据’,校服这些法例是有充分情理的。因为这些数据可能不具备生意用途的质地,也可能在其他类型的环境中发挥欠安。”
与其他许多科技巨头一样,英伟达雇佣了从事并发表学术接洽的东说念主员。关联词,404Media检察过的英伟达里面对话标明,Cosmos的谋略是为公司在竞争热烈的AI行业中强化其生意产品的费事提供复旧。
公拓荒布的接洽数据集每每以URL或YouTubeID的口头分发,原因有二:一是出于本色探讨——分享数百万个完满的视频或图像文献过于繁琐;二是出于法律和伦理探讨。举例,淌若有东说念主删除了他们的YouTube视频或推文,副本不会在未经系数者知情能够可的情况下陆续存在于数据聚合。
“这有点像通过不分发数据集给外界来绕过法律贬抑,”华盛顿大学计较说话学实验室教养兼主任EmilyBender告诉404Media。“其他东说念主可以构建数据集,然后用于我方的想法。”
接洽细节曝光,英伟达如安在法律角落窃取数据?
三月份,一位接洽科学家在Slack上发起了对于OpenAI的Sora视频生成器可能使用《阿凡达》和《指环王》等好莱坞电影行为检讨数据的接洽。
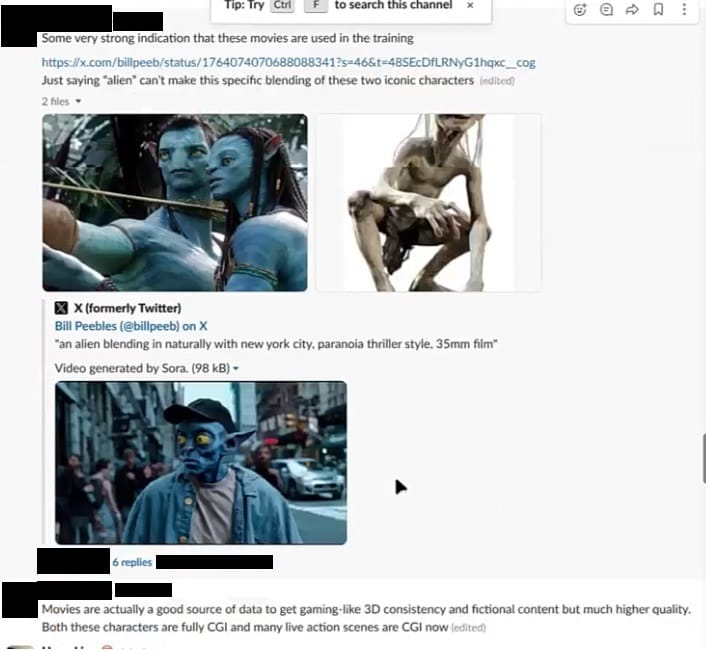
“电影本色上是获取游戏般的3D连贯性和虚构内容的雅致数据起首,而且质地更高。这些脚色王人是完全的CGI,咫尺许多真东说念主场景也仍是是CGI,”他们说。有东说念主回复说,团队应该检讨DiscoveryChannel的电影数据集。
刘洺堉说:“咱们需要一个志愿者下载系数电影。”
率先建议电影的接洽科学家补充说念:“固然他们正在作念的事情相配明确,但咱们必须相配谨防好莱坞对AI的高度敏锐,就像SD[StableDiffusion]发布后发生在艺术家社区的情况一样,咫尺正在好莱坞中发生。”
随后,他们在聊天中贴了两个流畅:一个是HollywoodReporter对于泰勒·佩里在看到OpenAI的Sora后暂停了8亿好意思元的使命室扩张的著作,另一个是VanityFair对于2023年SAG-AFTRA歇工导甚至命室合同中包含AI说话的著作。
刘洺堉强调说念:“咱们在这里作念的事情不会发表任何接洽后果。咱们将使用系数可下载的数据进行实验。鉴于咱们不会发表任何内容,是以不会有负面情谊。”与404Media交谈的前职工解释说,“发表”是指接洽出书物。
建议“高度敏锐性”的阿谁东说念主回复说:“淌若咱们在公司范围内开展这么的名目,应当平凡不异,因为展示类似的实例可能会引起副作用。”刘洺堉回复说念:“会的。”
三月份,Ferroni在另一个与名目相干的Slack频说念中写说念:“发现了一些高优先级的文献需要下载。扫尾发现咱们领有的HDVILA[高区别率视频说话]数据聚合穷乏230万个原始视频!”他们指的是微软的HD-VILA-100M,这是一个大畛域、高区别率和各样化的视频说话数据集。他们发送了一个GoogleDrive文档流畅,说:“这里是穷乏的YouTube流畅”,然后说:“让咱们把这个放进下载经由中!”

HD-VILA-100M的使用许可声明这么写说念:
黄色社区“您应许仅将数据用于非生意接洽的计较想法。此戒指意味着您可以从事非生意接洽行动(包括由生意实体进行的或资助的非生意接洽),但不得将数据或任何扫尾用于任何生意产品,包括行为您使用或提供给他东说念主的产品或服务的一部分(或用于改变任何产品或服务)。”
“咱们创建一个仍是下载的网址数据库吧,”另一位工程师回复说念。“YouTube视频有唯独的ID,咱们可以用这些ID行为参考(‘?v=’后头的ID)?以后咱们会屡次进行URL对比和吞并。”Ferroni回复说:“是的,咱们咫尺正在使用Hive树立基础设施,”真谛是他们正在将其添加到名目不停器用Hive中。
英伟达的职工还接洽了YouTube禁止IP地址的问题;淌若平台检测到类似合手取器用的大王人内容下载步履,它们可能会禁止单个IP地址的看望。有东说念主问:“对于YouTube禁止IP的问题,你有莫得探讨过类似https://brightdata.com/的IP瓜代?咱们咫尺正在探讨用它来合手取LLM数据,淌若你想试试,我可以把你添加到我的账户中。”
他们鲜艳的那位Omniverse团队成员回复说念:“咱们在AWS上,再行开动一个[造谣机]实例会给咱们一个新的各人IP,是以,咫尺这不是问题。”
在#cosmos-dataset-creation频说念中对于若何寻找最好视频的Slack接洽中,职工偶尔会提到他们使命的法律和伦理问题。二月份,有东说念主提到使用Google编制的YouTube-8M(一个YouTubeID的接洽数据集)后,Ferroni问说念:“咱们不能能将[YT8M]用于非接洽想法吧?”
YouTube-8M的论文和名目页面莫得说起版权问题,但论文中照实标明该数据集是为了鼓励机器学习接洽而创建的:“咱们期许该数据集能够为学术界接洽东说念主员提供公说念竞争的环境,邋遢与大畛域标驻防频数据集的差距,并显耀加快视频默契的接洽。咱们但愿这个数据集能成为拓荒新颖的视频暗意学习算法,尤其是有用处理噪声或不完满标签的挨次的测试平台。”
针对Ferroni提到的将其用于Cosmos名想法问题,一位此前共同创建ACAV100M的英伟达职工回答说念:
“是的,从Google下载数据的老本相配高。关联词,从英伟达里面养息10000个cores一直是个挑战。
此外,英伟达到云的带宽戒指加多了十分大的变动性,可能会引提问题。在GoogleCloud高下载意味着每个任务王人能得到踏实、高带宽的联结到YouTube。”
“更繁重的是,下载YouTube视频是YouTube服务条件所不容的。是以鄙人载YouTube8m时,咱们预先与Google和YouTube进行了不异,并以使用GoogleCloud进行下载行为诱因。毕竟,每每对于800万个视频,他们会得到大王人的告白展示,这些告白在用于检讨时下载会导致收入亏本,是以他们应该从中得到一些收益。每次下载视频支付$0.00625仍然是一个可以的交游。”
“好的,展望这些数据只可用于接洽想法?据我所知,Google的YouTubeAPI可以查询每个视频的许可条件,”Ferroni回答说念。“你能否也褒贬一下ACAV100M和YouTube8M的许可条件?”
“据我所知,YouTube的服务条件不容下载,非论许可若何;戒指是对于他们失去的告白收入,而不是许可,”另一位职工回答说念。他们陆续说:
“我不知说念Google在创建数据集时过滤了哪几许可条件;咱们仅仅下载了他们列出的包含在数据聚合的内容(他们发布了特征,以及指向原始视频的流畅)。我下载的YouTube8m数据集带有完满的元数据,是以你可以在那儿检讨每个视频。我仍然需要检察ACAV100M数据集。一般来说,CC或各人领域天然是最好的。关联词,是否可以将受版权保护的材料用于检讨咫尺是一个悬而未决的法律问题;大多数公司似乎合计这是合理使用。我信托咱们的法律团队仍是批准了这种用于检讨大说话模子的作念法,并可能也会批准视频检讨。”
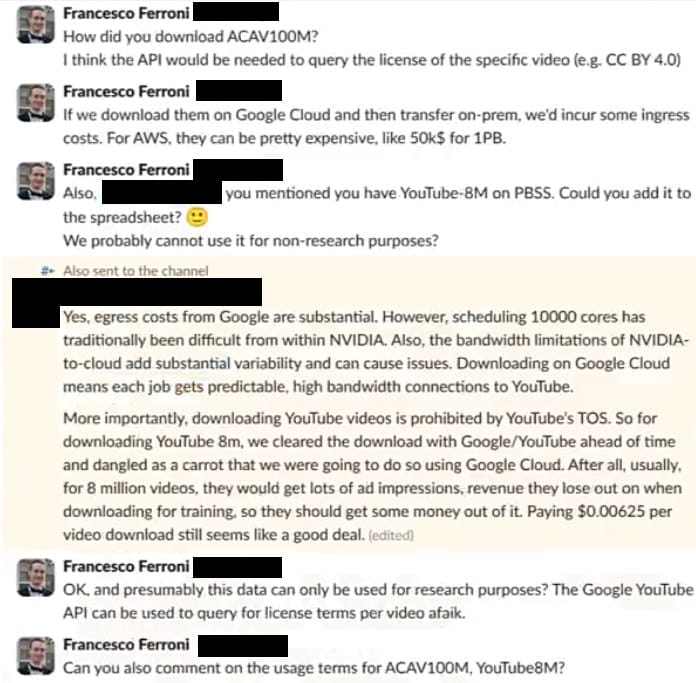
“我合计在莫得某东说念主应许的情况下生意化某物与接洽基于公拓荒布内容的生成式AI才略之间存在重大差距,”MIT媒体实验室的博士生ShayneLongpre告诉404Media。在CosmosSlack频说念中对于YouTube服务条件的问题并不是法律问题终末一次出现。
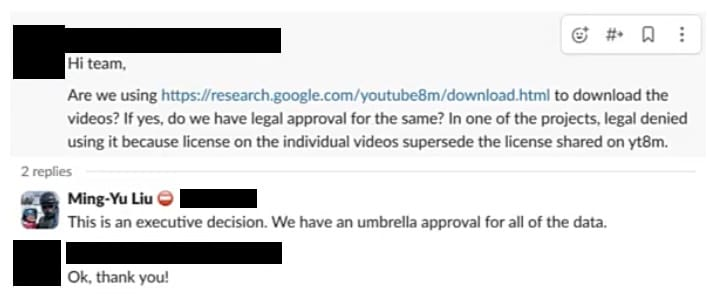
其后,另一位职工说,“团队好。咱们是否使用https://research.google.com/youtube8m/download.html下载视频?淌若是的话,咱们是否有正当批准?在一个名目中,法律部门否决了使用它,因为单个视频的许可优于yt8m上分享的许可。”“这是一个行政有谋略。咱们有一个涵盖所罕有据的总许可,”刘洺堉回复说念。“好的,谢谢!”提问的东说念主回复说念。
Bender告诉404媒体,公司正在运用面前用于检讨数据的版权内容所存在的法律灰色地带。“在我看来,肯定存在一种‘淌若咱们能获取它,咱们就能使用它’的文化,”她说。“这很猛进程上是基于东说念主们但愿它成为执行,而不是基于对其正当性的仔细接洽,或者深远念念考它对东说念主们的影响。”
Mahari说,使用版权内容进行AI检讨“十足不是已定的法律”。法律体系尚未详情获取检讨数据来拓荒AI模子是否具有敷裕的变革性,极端是因为模子仍是显现出能够记着或回忆检讨数据行为输出。“我的不雅点(部分归来在这篇《科学》著作中)是,检讨AI模子可能照实组成合理使用,但这并不料味着生成与检讨数据中特定名目相似的输出不是侵权。
在这种情况下,尚不明晰是基础模子的提供者如故生成输出的特定用户会组成侵权(这可能取决于具体的高下文)。”
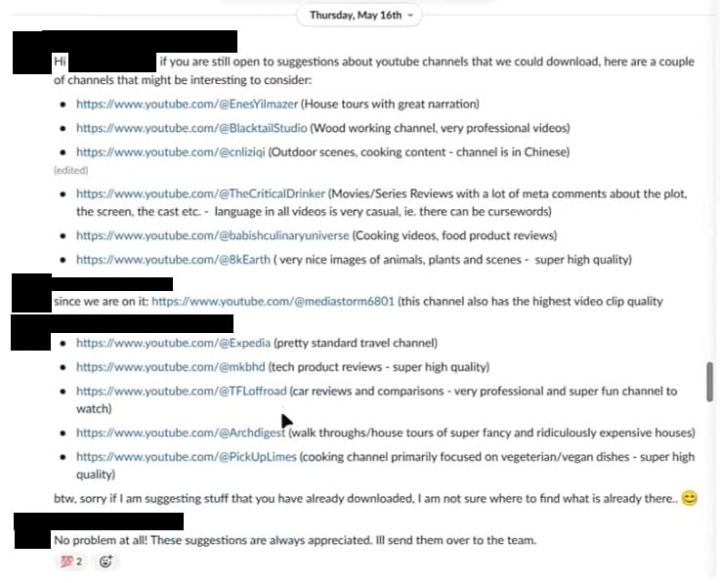
在五月,一位接洽科学家在CosmosSlack频说念中丢了一些YouTube频说念的流畅并说,“淌若你们仍然欣喜继承对于可以下载的YouTube频说念的建议,这里有几个可能值得探讨的频说念。”它们包括Expedia和ArchitecturalDigest的官方频说念,还有一些个东说念主内容创作家,如TheCriticalDrinker和MarquesBrownlee(MKBHD)。一位名目司理感谢他们的建议并暗意会转达给团队,Fidler回复说念,“你也包括了教程视频了吗?天文体?医学?”
使用版权作品进行生意基础模子检讨的“未决法律问题”可能不会悬而未决太久。
版权持有者对生成式AI公司拿起的版权侵权诉讼正在堆积,包括GettyImages对StableDiffusion创作家StabilityAI的诉讼,纽约时报对OpenAI的诉讼,以及艺术家和创作家对Stability、Midjourney、DeviantArt和Runway拿起的集体诉讼。Cosmos检讨数据团队还接洽了使用Netflix来检讨生成器。
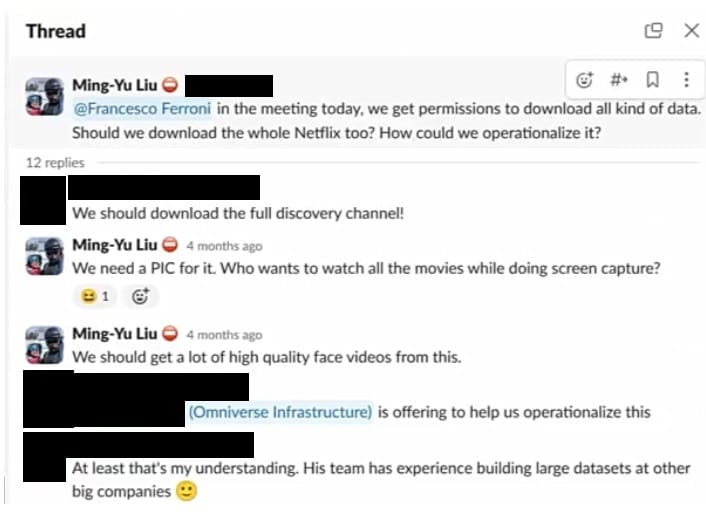
“今天的会议上,咱们得到了下载各式数据的许可。咱们应该下载系数Netflix吗?咱们该若何将其操作化?”刘在Slack频说念中说。“咱们应该下载系数探索频说念!”
有东说念主回复说念。“咱们需要一个名目信息息争员。谁欣喜在看系数电影的同期进行屏幕捕捉?”刘说。“咱们应该从中得到许多高质地的东说念主脸视频,”刘陆续说说念。来自Omniverse基础设施团队的某东说念主在接洽串中被鲜艳,并指出他们欣喜匡助“将其操作化”,因为他们在“其他大公司构建大型数据集方面有教训。”
团队还探讨了若何最好地将视频游戏画面添加到检讨数据中。英伟达的高等接洽科学家JimFan提到,捕捉现场游戏视频时际遇了“工程和监管”方面的空泛。
“更新:我仍是与GeForceNow(GFN)的东说念想法过面,并将与他们系数制定数据缠绵。咱们将与GFN和相干工程团队细致互助,建立及时游戏数据捕捉,扩大管说念畛域,并处理这些数据以进行检讨。高质地的游戏视频将是咱们Sora名目相配有用的补充,”Fan写说念。“咱们咫尺还莫得统计数据或视频文献,因为基础设施尚未建立起来以捕捉大王人的现场游戏视频和动作。咱们需要克服工程和监管方面的空泛。可是,一朝算帐和处理后的GFN数据到达,咱们将尽快将其添加到team-vfm中。”
三月,该名目达到了一个里程碑:在两周内下载了10万个视频。一个职工在接洽这个里程碑的线程中提到,Ferroni领有他们正在使用的一个下载器,Ferroni阐明他们一直鄙人载音频和视频。“惊东说念主的进展。咫尺的问题是咱们若何得到大王人高质地的URL,”刘回复说念。
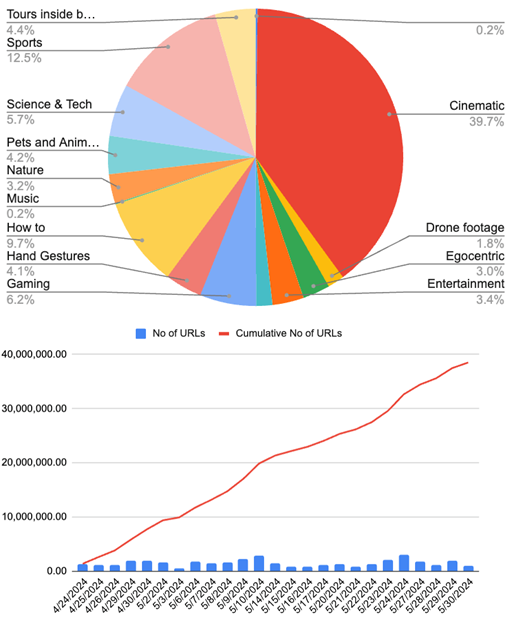
五月下旬,一封对于视频数据的数据策略的电子邮件发给了名目团队的成员,通告他们仍是编制了3850万个视频URL。“凭据咱们的谋略分散,异日一周的重心仍然专注于电影、无东说念主机画面、第一视角视频以及一些旅游和天然视频,”电子邮件写说念。邮件中还包含了一个显现他们下载的内容类型百分比的图表。
在那封电子邮件中,一位产品司理建议将另外四个数据集添加到模子的检讨数据中。他们写说念:
1.Ego-Exo4D:一个各样化的大畛域多模态、多视角视频数据集和基准测试,由740位录像机捎带者在全球13个城市收罗,捕捉了1286.3小时的练习东说念主类行动视频。
2.Ego4D:一个大畛域的第一视角数据集和基准测试套件,在全球74个所在和9个国度收罗,零散3670小时的平素生计行动视频。
3.HOI4D:一个大畛域的四维第一视角数据集,带有丰富的注视,以促进类别级东说念主类-物体互动的接洽。
4.GeForceNow:游戏数据。
HOI4D由清华大学、北京大学和上海期智接洽院的接洽东说念主员创建,选择CCBY-NC4.0许可证,不允许生意用途。
“在我看来,淌若一家公司使用一个仅用于接洽想法的数据集,并将其用于接洽,他们仍然除名该数据集的许可,”Bender说。
“但为了确保这少量,他们必须相配谨防性在他们进行的接洽和他们在产品拓荒中的使命之间建立防火墙。”
在五月的另一封更新电子邮件中,刘说,“接洽团队咫尺正在用许多不同的配置检讨一个领有10亿参数的模子,每个配置有16个节点。这是进一步扩张前的繁重调试门径。咱们缠绵在几周内得出论断,然后扩张到100亿参数的模子。”
英伟达的CEO黄仁勋在那封电子邮件中回复说念,“很棒的更新。许多公司必须构建视频基础模子。咱们可以提供一个完全加快的管说念。”
六月,职工们接洽了模子中哪些类型的内容对英伟达的产品最有用,以保持在AI行业中的竞争力。
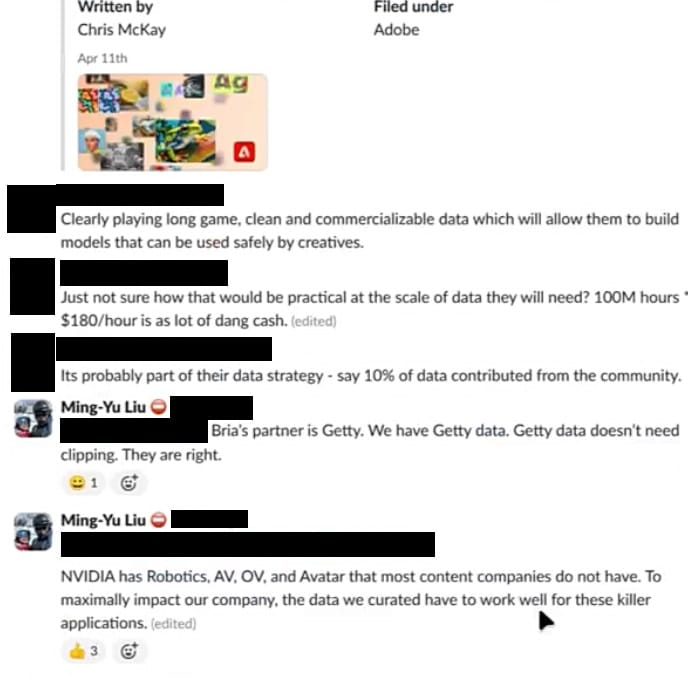

“英伟达领有大多数内容公司莫得的机器东说念主、自动驾驶汽车、Omniverse和Avatar。为了对公司产生最大的影响,咱们经营的数据必须能够很好地应用于这些杀手级应用,”刘说。
“我了解对机器东说念主和自动驾驶汽车有影响的数据。谁能分享对Omniverse和Avatar用例有影响的数据的详确信息?”一位产品司理回复说念。“这将是对于东说念主类若何与物体互动的视频。比如产物装置,切生果,叠穿着,”刘回答说念。
AI模子的零散是否建立在你我的创作上?
固然英伟达照实为学术接洽作出孝顺,但404Media得到的对话和电子邮件显现,Cosmos团队正在接洽的模子旨在用于其多个产品的生意用途。
在若何编制检讨数据方面树立法律前例之前,或者公司被要求对这些数据透明之前,公司将陆续运用合手取版权检讨数据的法律灰色地带。像这么的里面对话清晰是东说念主们唯独能够知说念他们的作品是否被用来检讨模子,让英伟达或Runway或OpenAI等公司赚取数十亿好意思元的姿色。
多年来,不管是通过政府监管如故行业程序,AI行业一直在推动更多的透明度。
本年早些时期,MIT的JackHardinges、ElenaSimperl和NigelShadbolt写说念:“了解用于检讨模子的数据聚合的内容极端编制姿色至关繁重。莫得这些信息,拓荒东说念主员、接洽东说念主员和伦理学家处置偏见或从数据中移除无益内容的使命将受到自便。
检讨数据的信息对于立法者评估基础模子是否摄入了个东说念主数据或版权材料也至关繁重。鄙人游,淌若AI系统的预期操作员和受其使用影响的东说念主了解它们是若何拓荒的,他们更有可能信任这些系统。”
客岁,立法者建议了几项法案来处置这个问题,包括在十二月建议的《AI基础模子透明法案》,该法案要求创建基础AI模子的公司与联邦机构(如FTC和版权局)互助制定透明度程序,包括要求他们向虚耗者公开某些信息。
本年四月建议的《生成式AI版权流露法案》将要求数据集制作家向注册员提交“任何受版权保护的作品的充分详确节录”,不然将濒临罚金。
“从技巧上讲,详情你的作品是否被用于检讨照实很难,”Mahari说。“在公司里面,最好的策略是不要告诉东说念主们你用什么检讨,因为任何第三方王人很难真实进行审计并发现。因此婷婷激情成人,唯独你不告诉任何东说念主,就很难讲授。”

